CASA: Category-agnostic Skeletal Animal
Reconstruction
NeurIPS 2022
- 1 USTC
- 2 UIUC
Abstract
Recovering a skeletal shape of animals from a monocular video is a longstanding challenge. Prevailing animal reconstruction methods often adopt a control-point driven animation model and optimize bone transforms individually without consid- ering skeletal topology, yielding unsatisfactory shape and articulation. In contrast, humans can easily infer the articulation structure of an unknown character by associating it with a seen articulated object in their memory. Inspired by this fact, we present CASA, a novel Category-AgnoStic articulated Animal reconstruction method consisting of two major components: a video-to-shape retrieval process and a neural inverse graphics framework. During inference, CASA first retrieves an articulated shape from a 3D character assets bank so that the input video scores highly with the rendered image, according to a pretrained language-vision model. It then integrates the retrieved character into an inverse graphics framework and jointly infers the shape deformation, skeleton structure, and skinning weights through optimization. Experiments validate the efficacy of our method regarding shape reconstruction and articulation. We further demonstrate that we can use the resulting skeletal-animated character for re-animation.
Pipeline
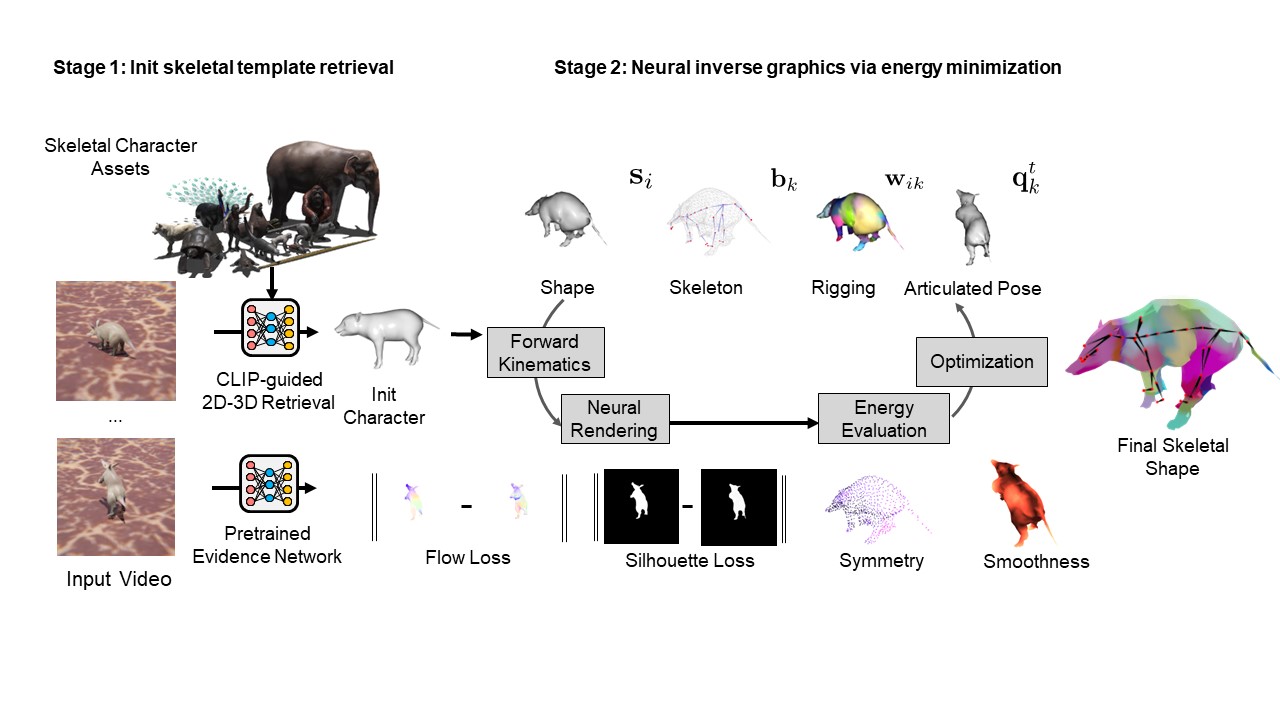
We first obtain an initial shape from our asset bank via 2D-3D retrieval. Then we integrates the retrieved character into an inverse graphics framework and jointly infers the shape deformation, skeleton structure, and skinning weights through optimization
Results on Synthetic Dataset

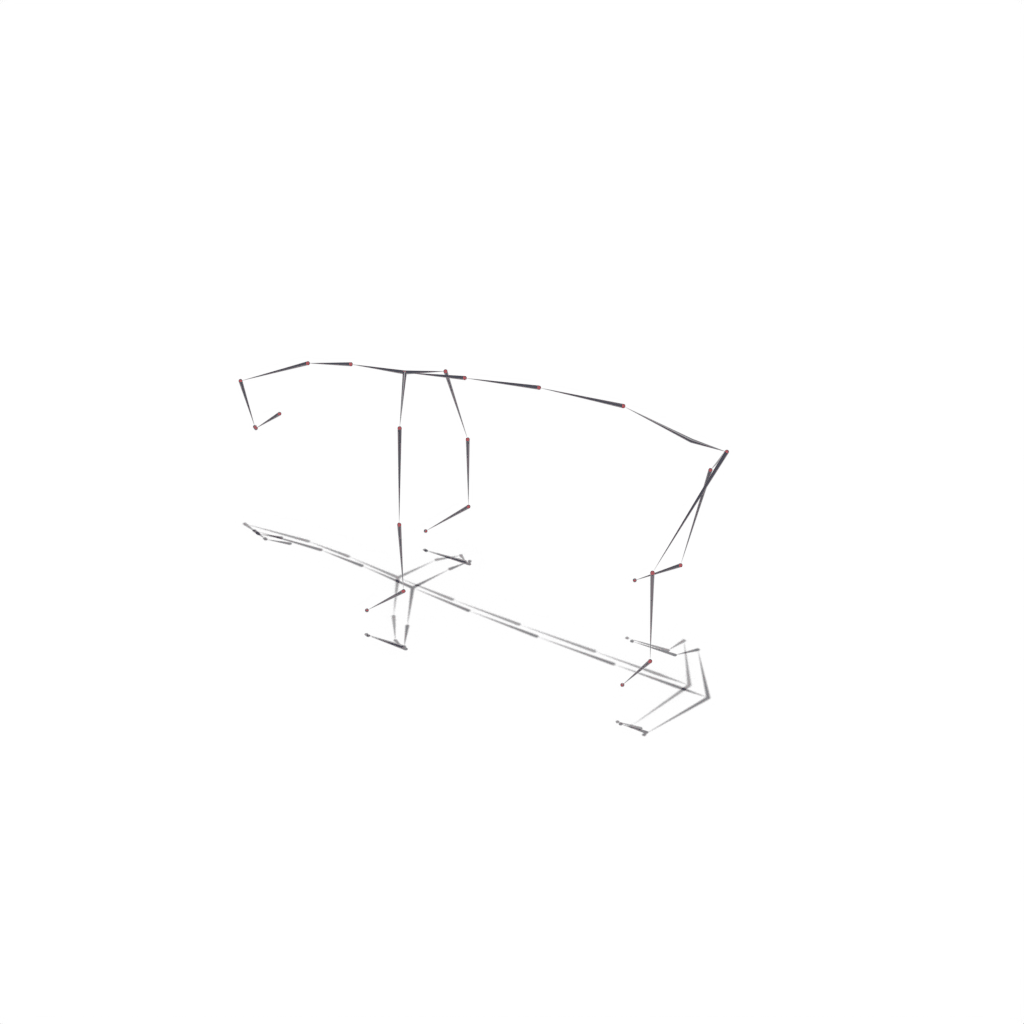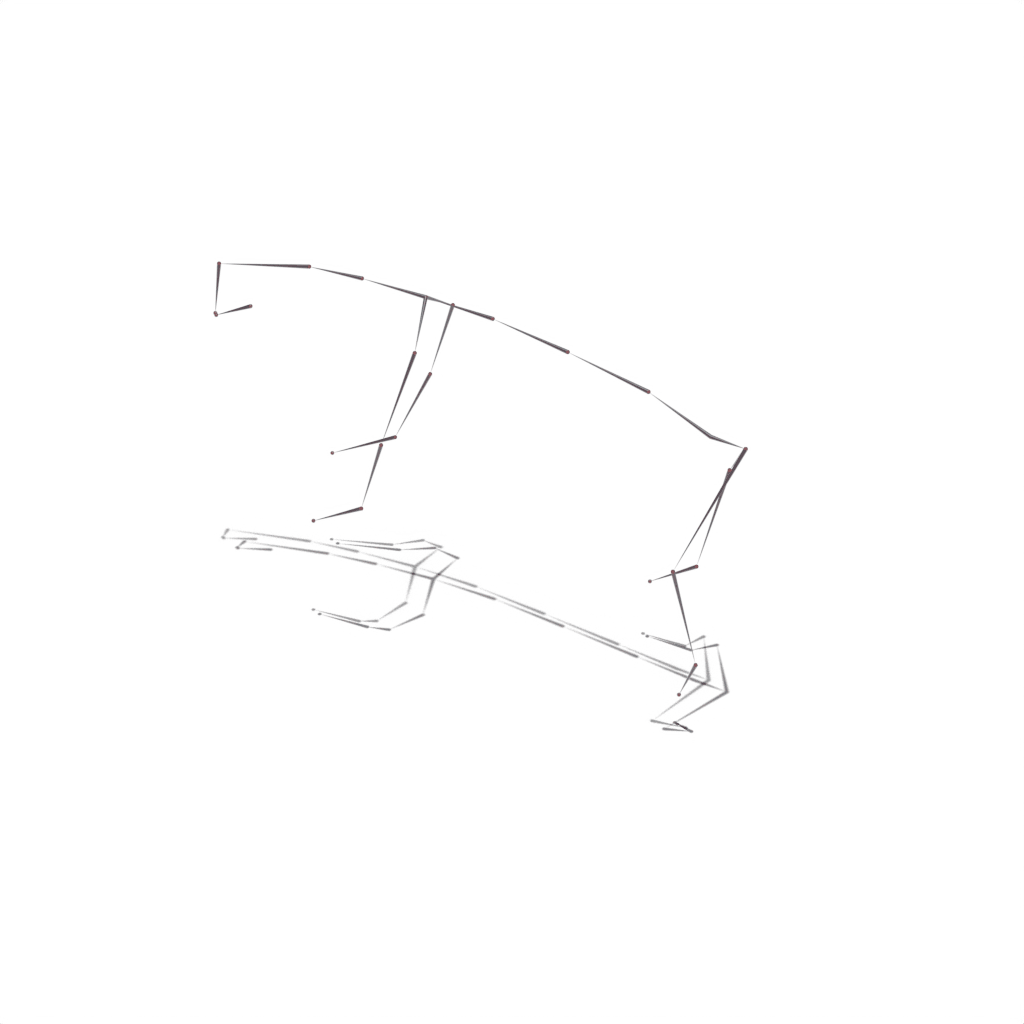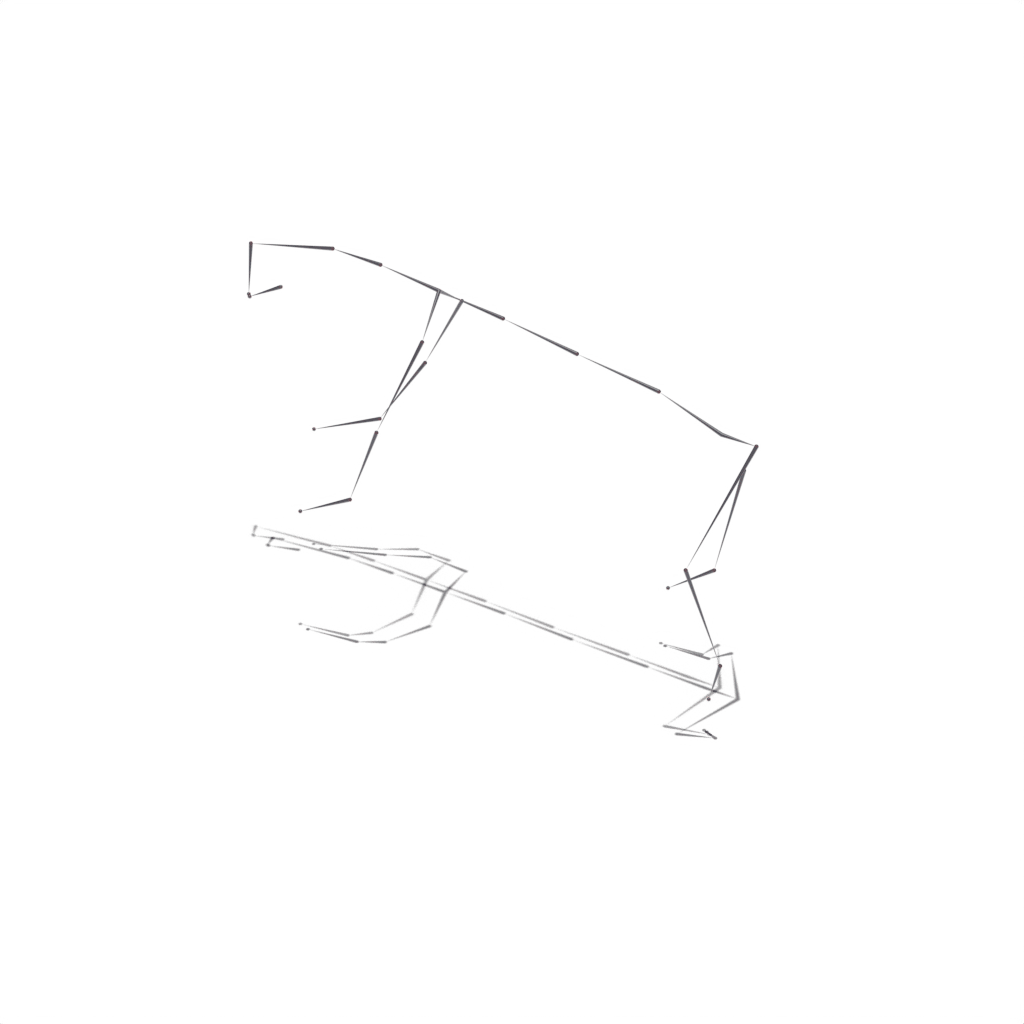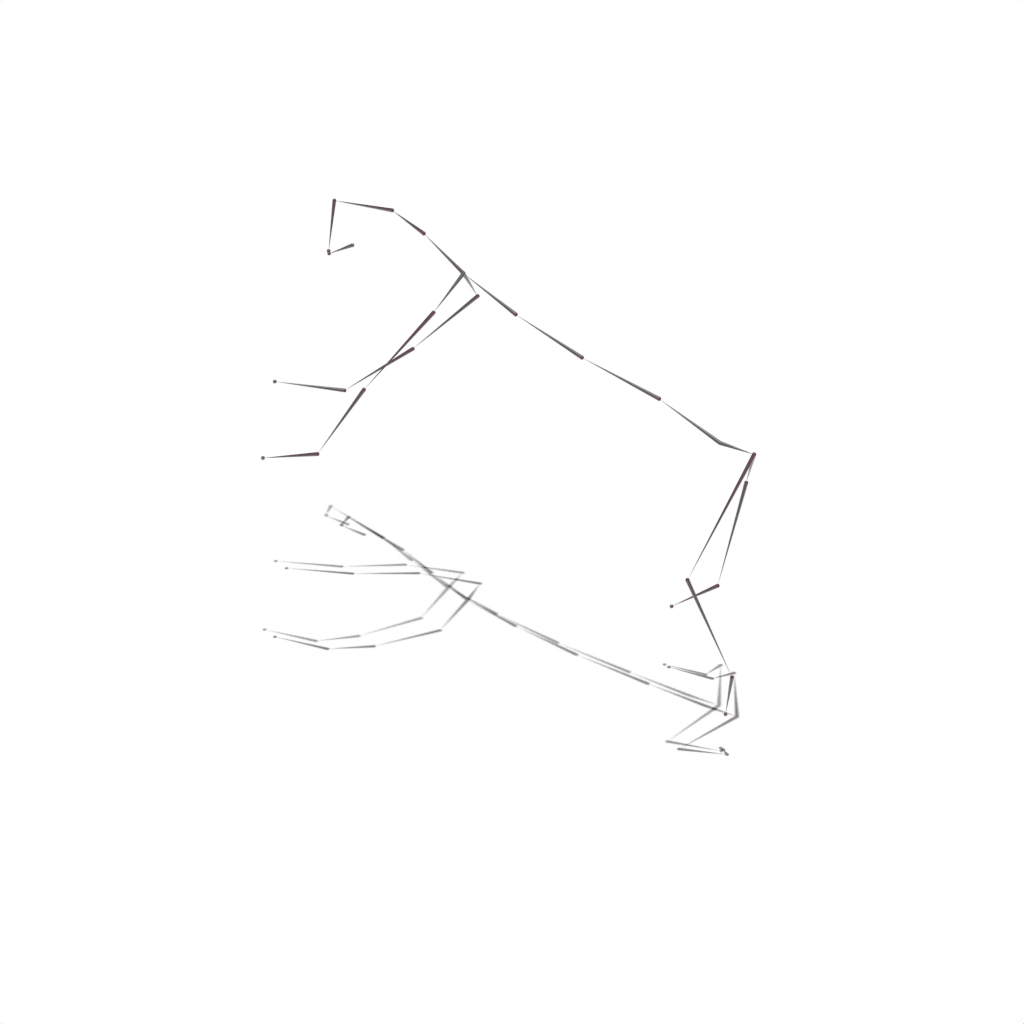


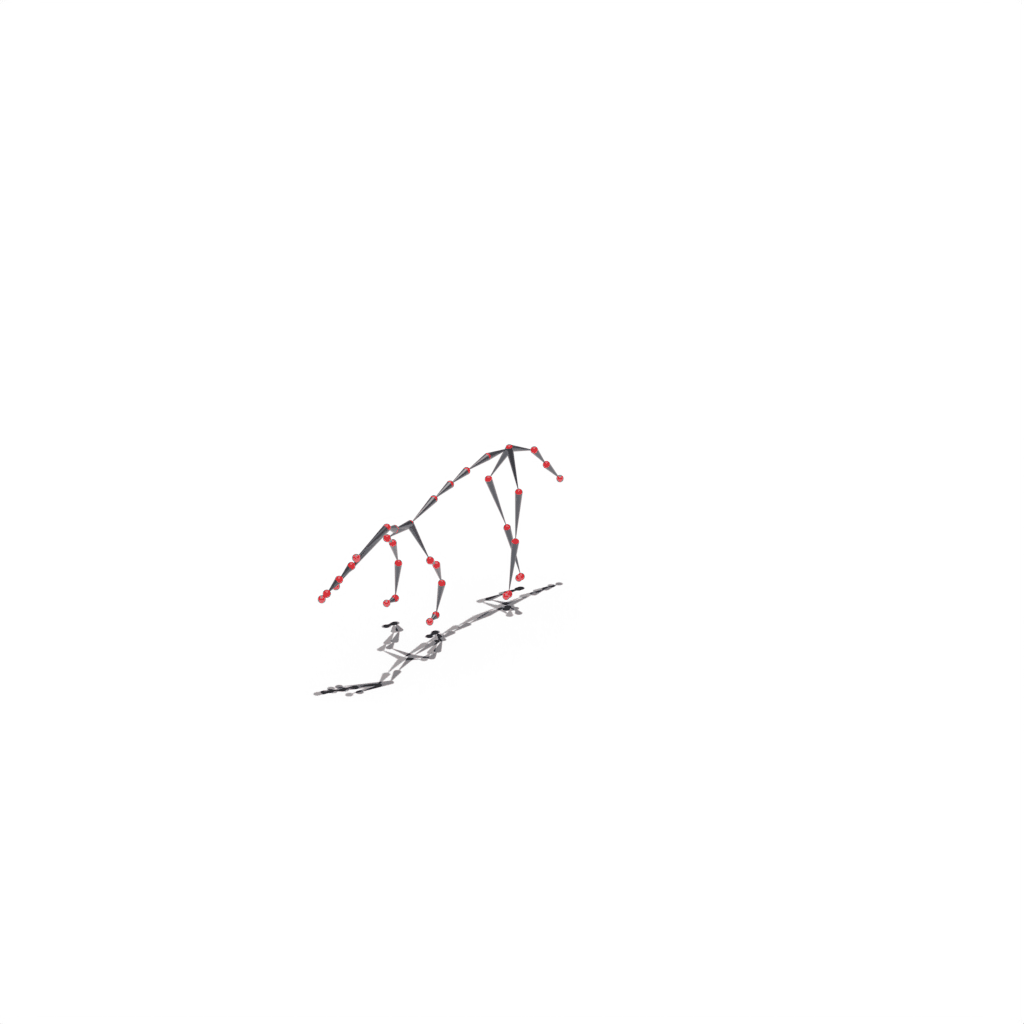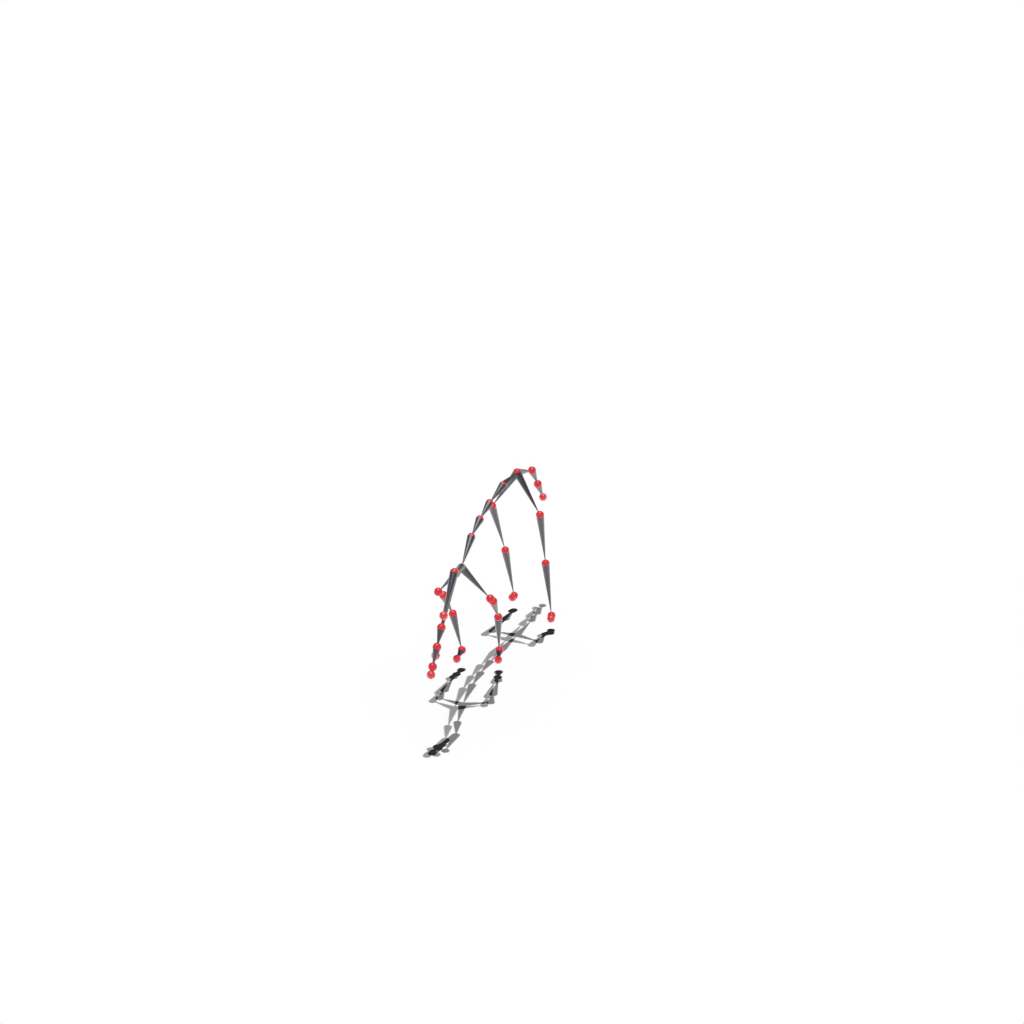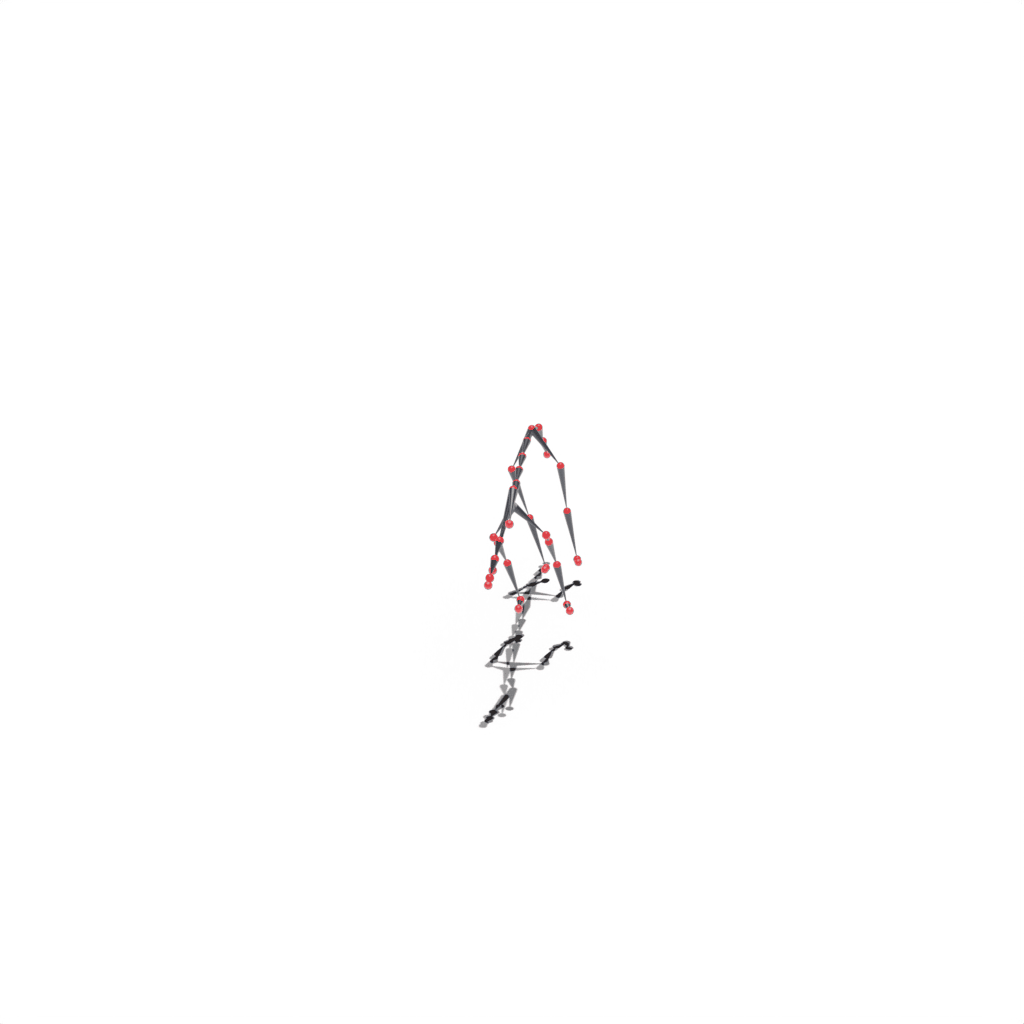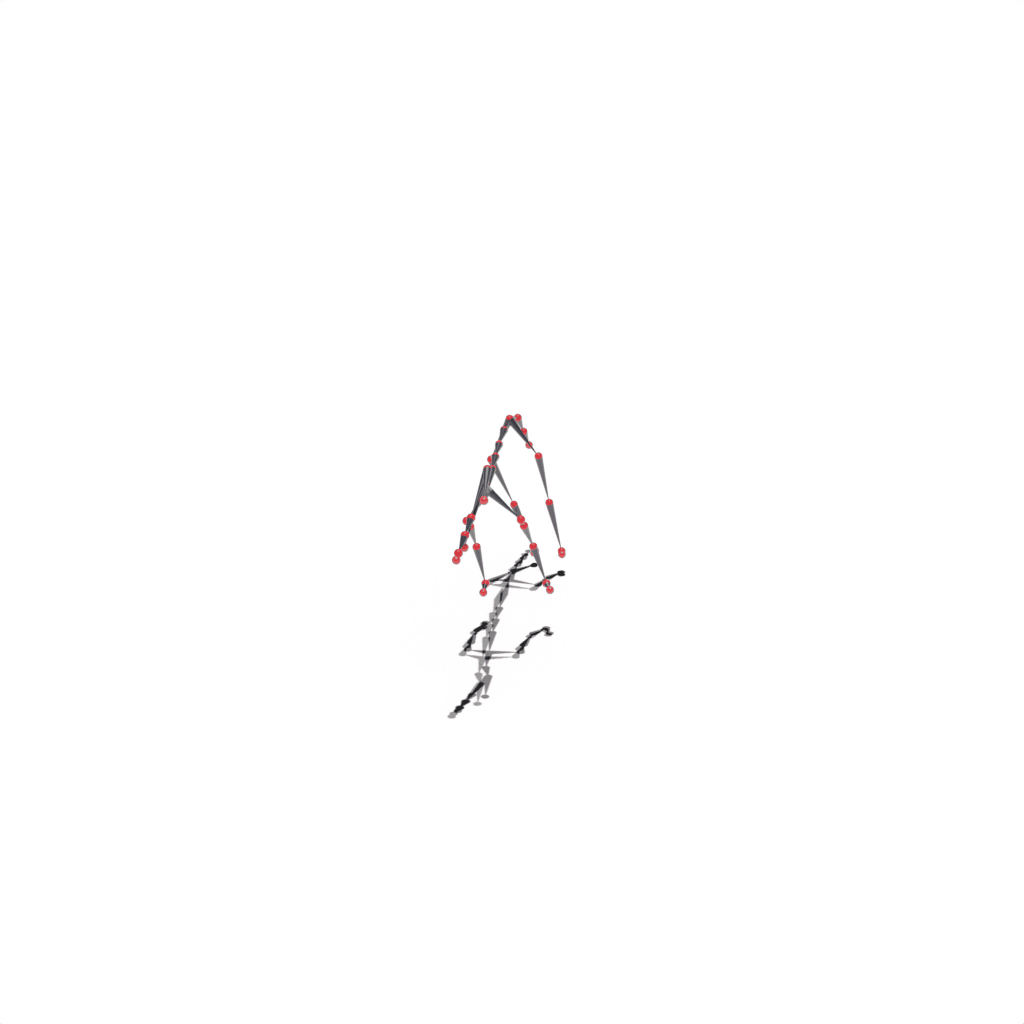
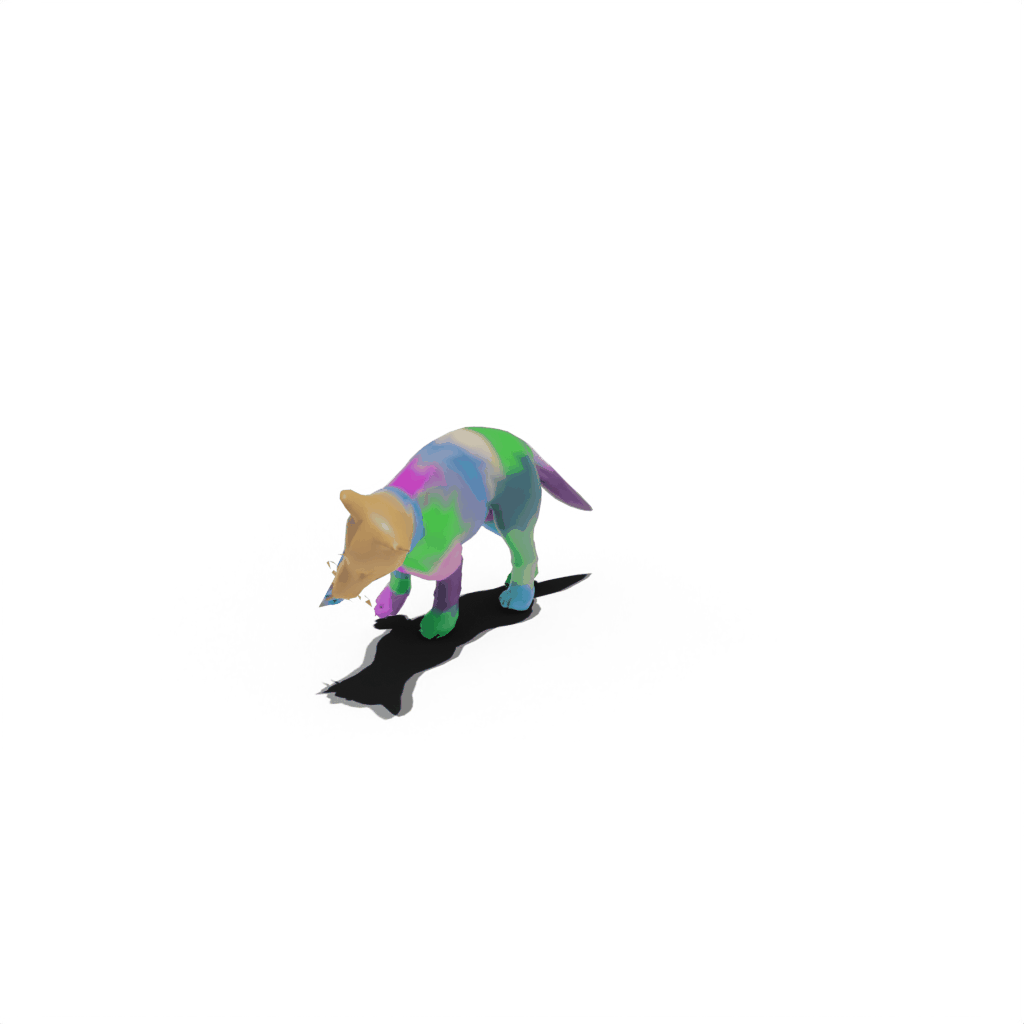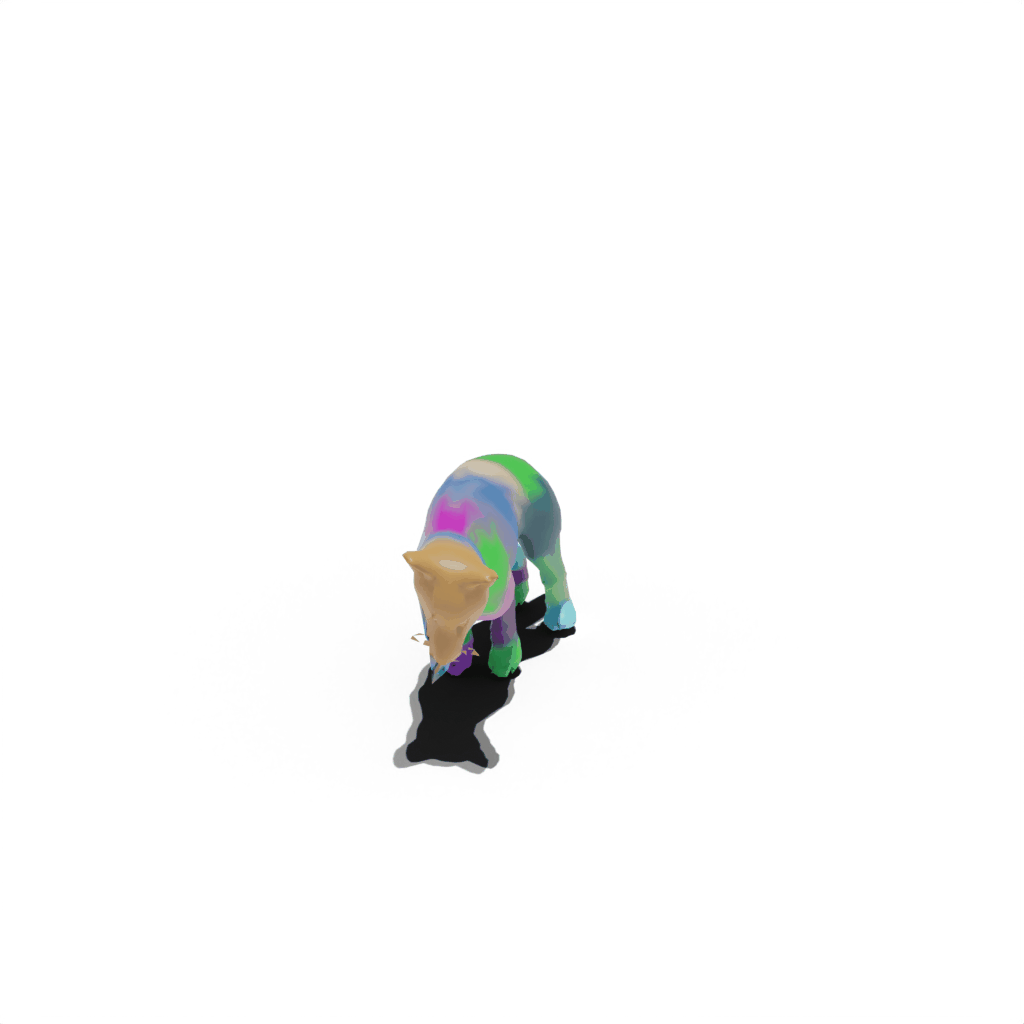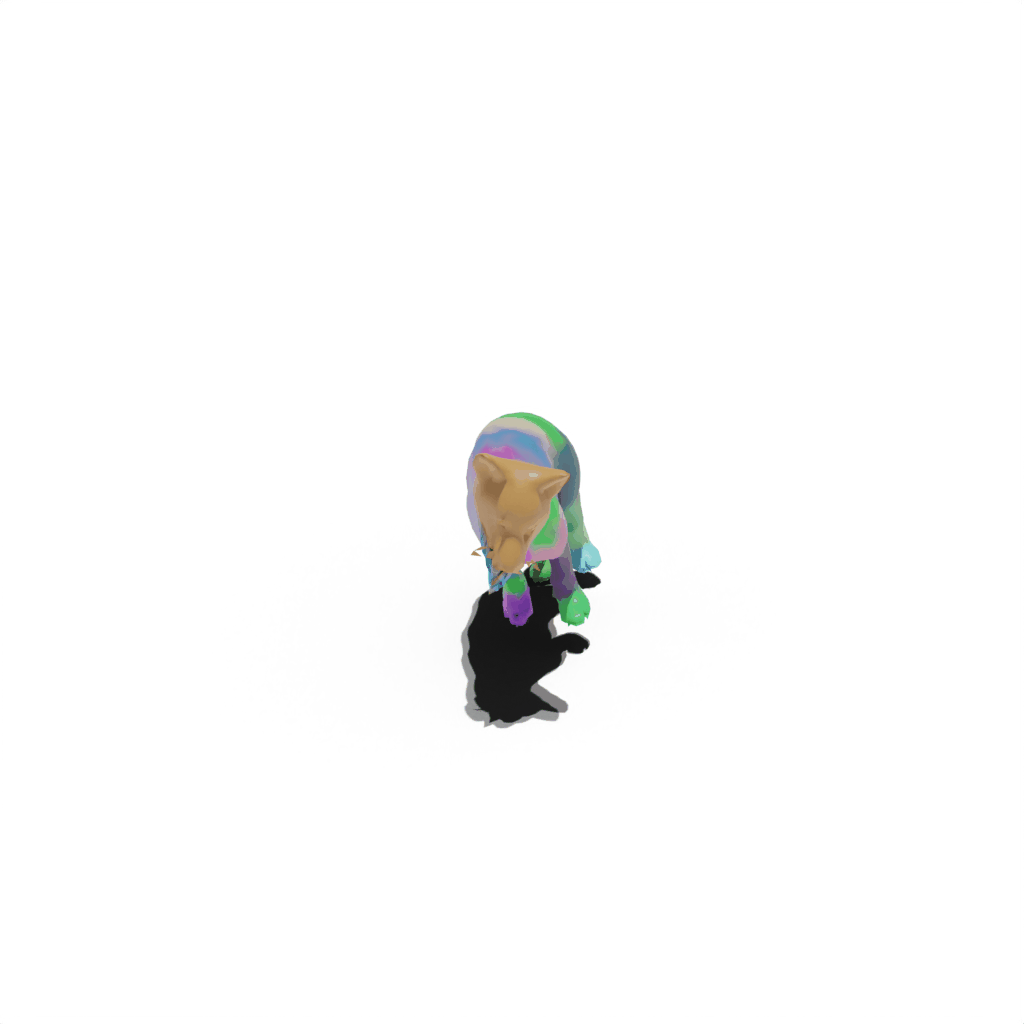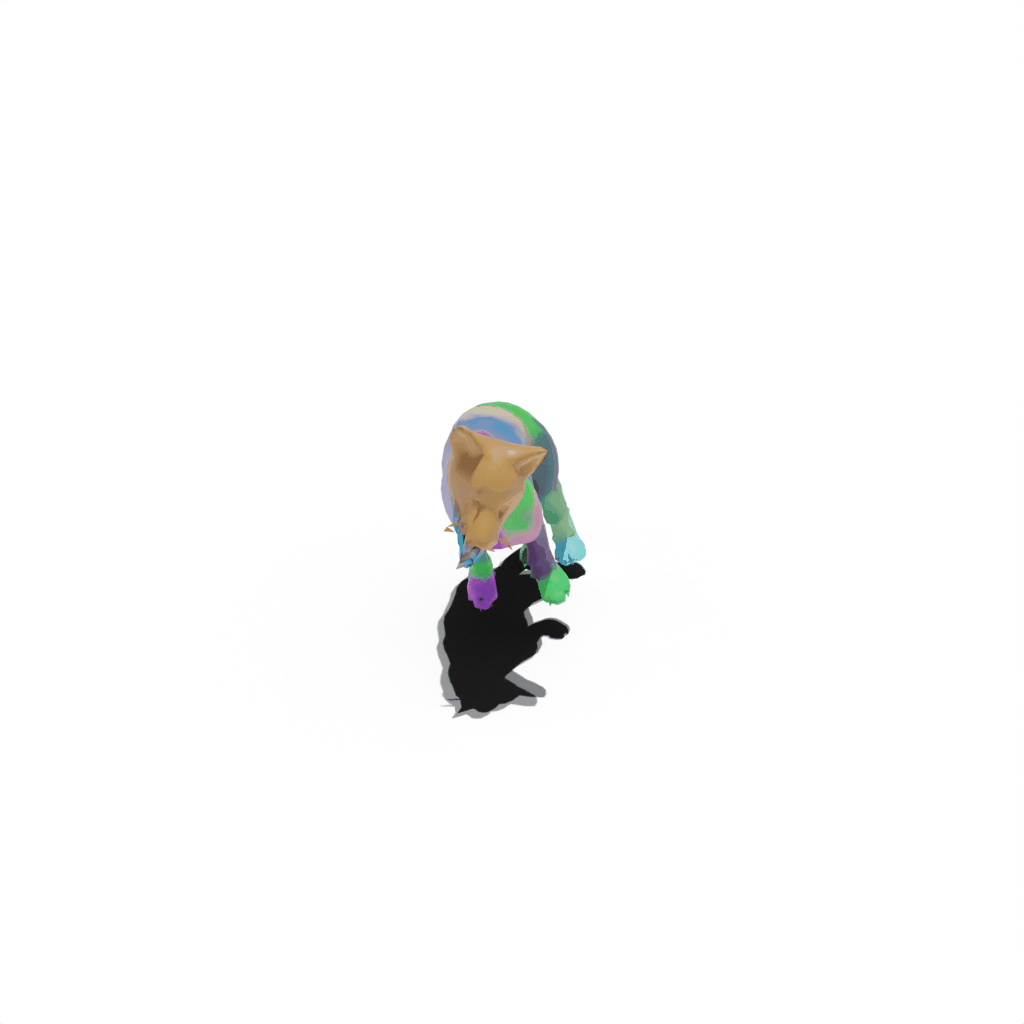

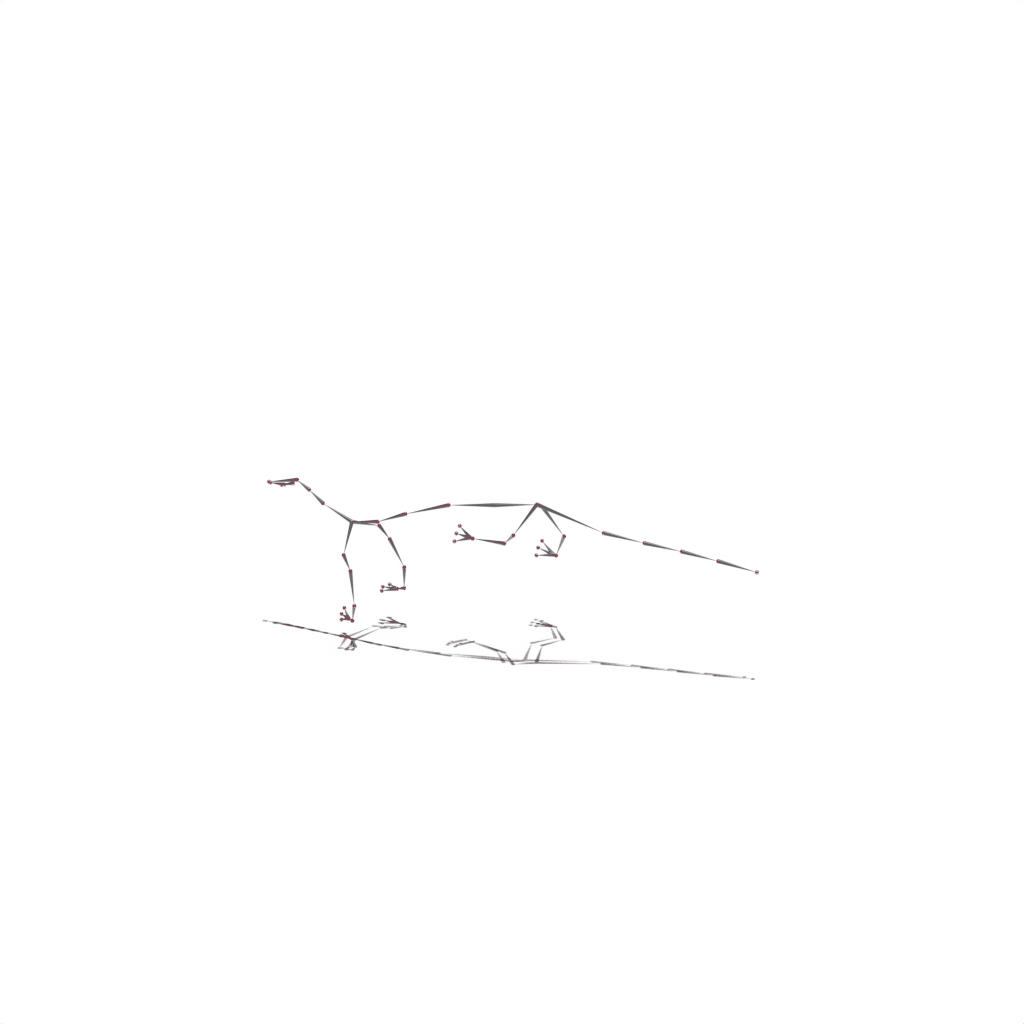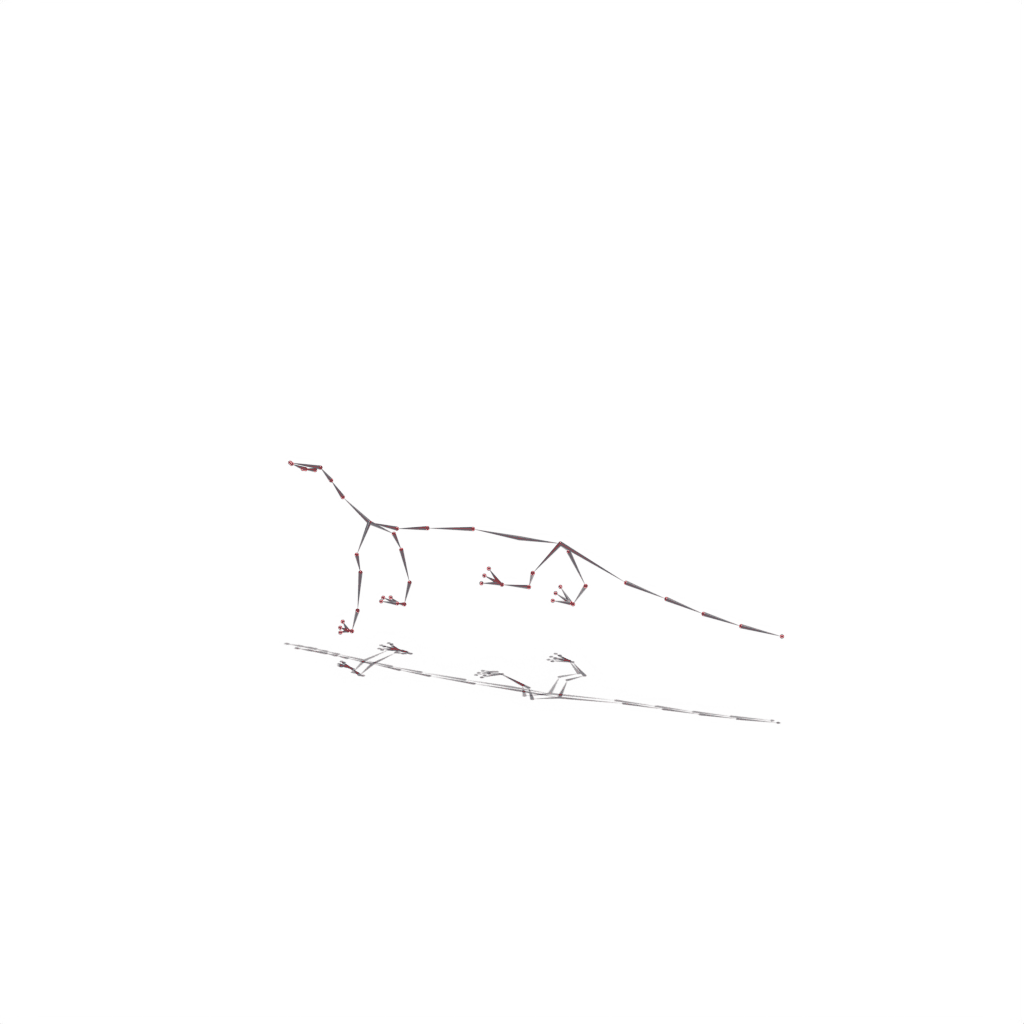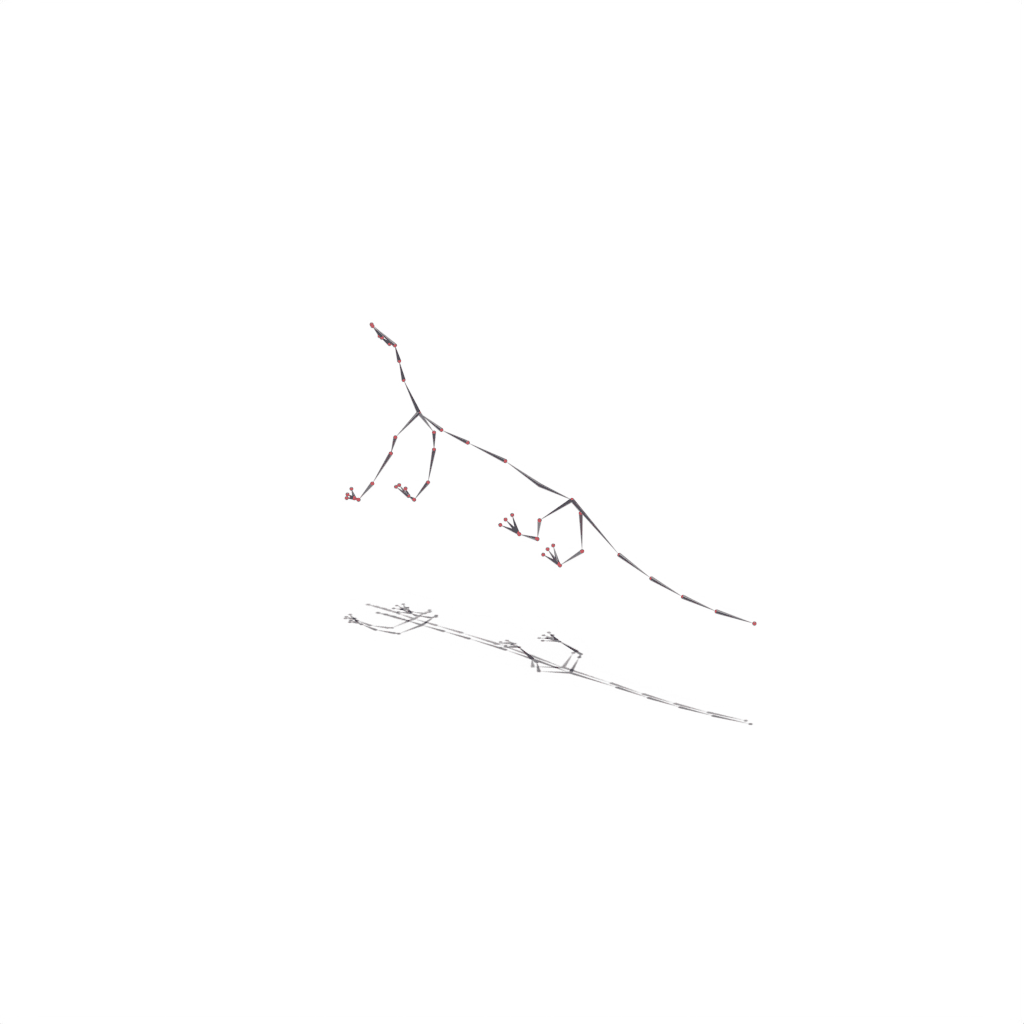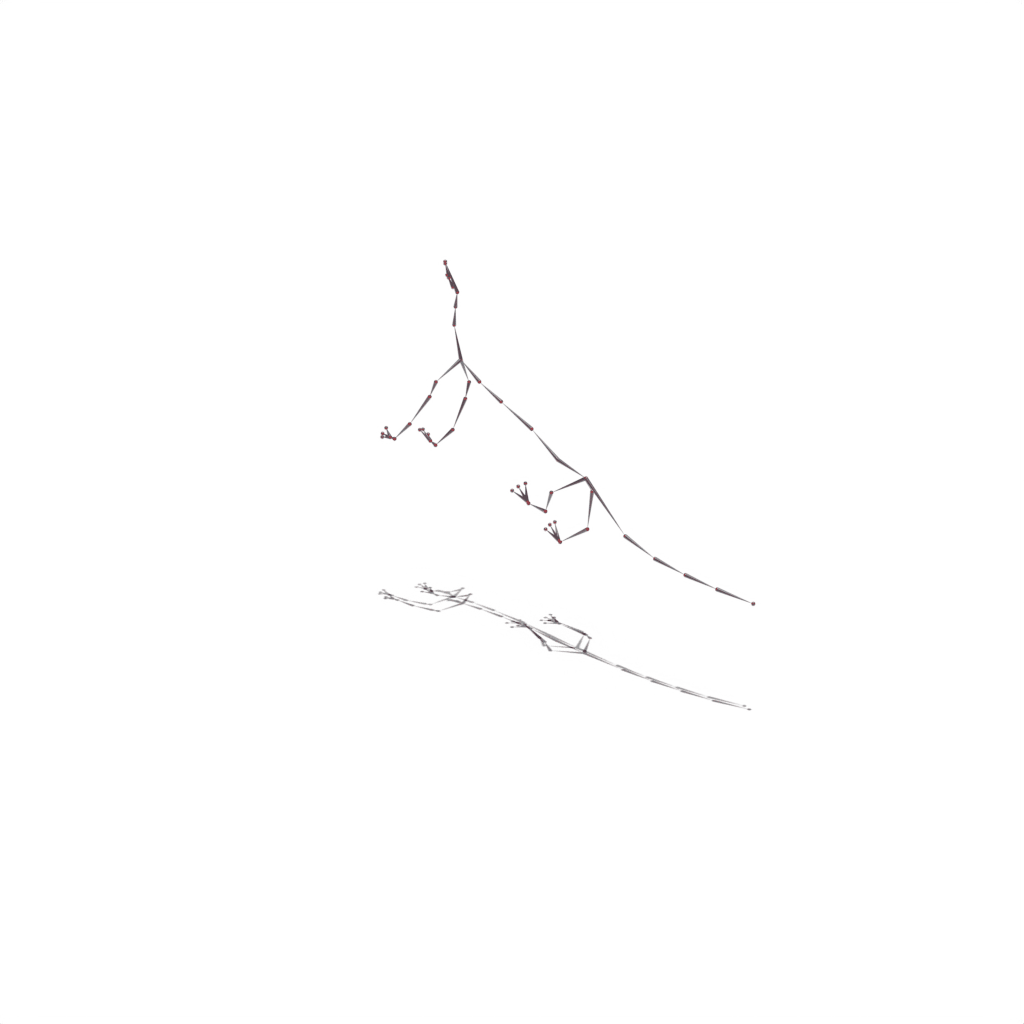
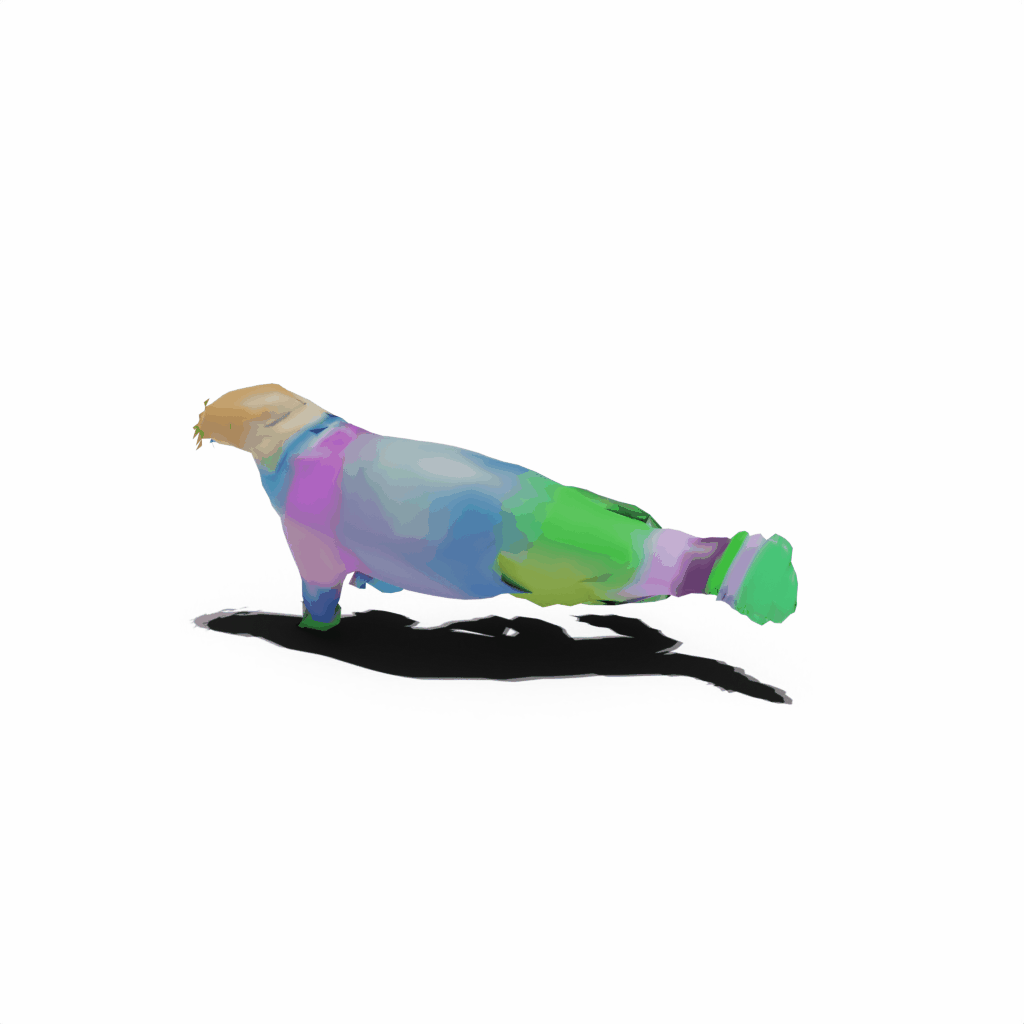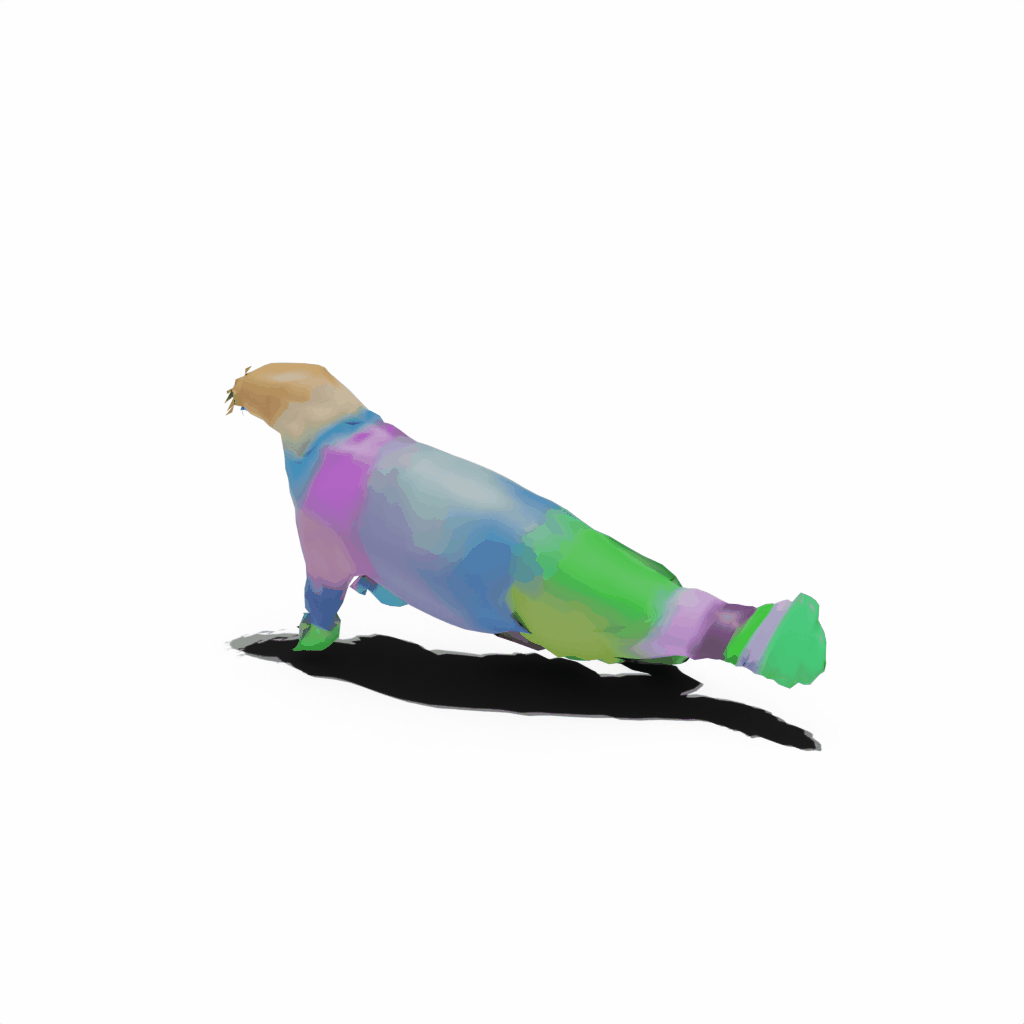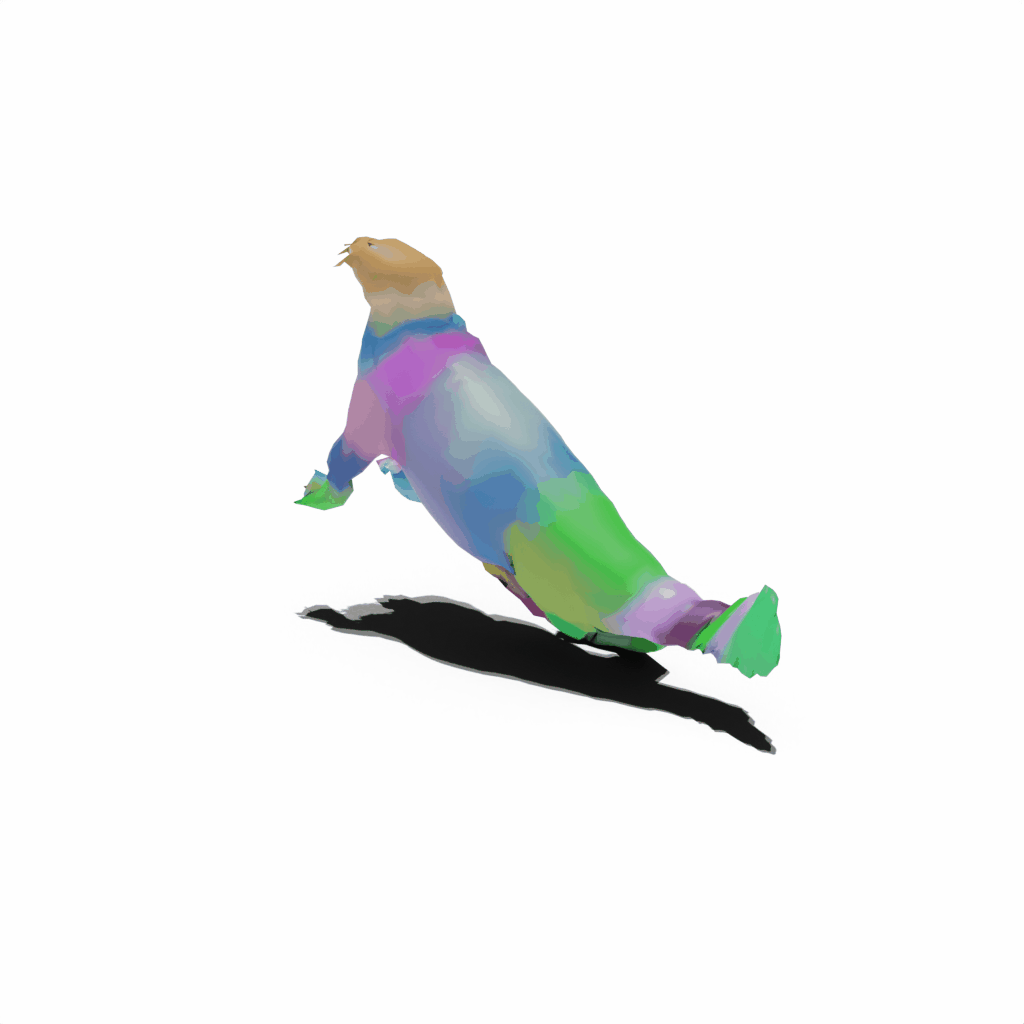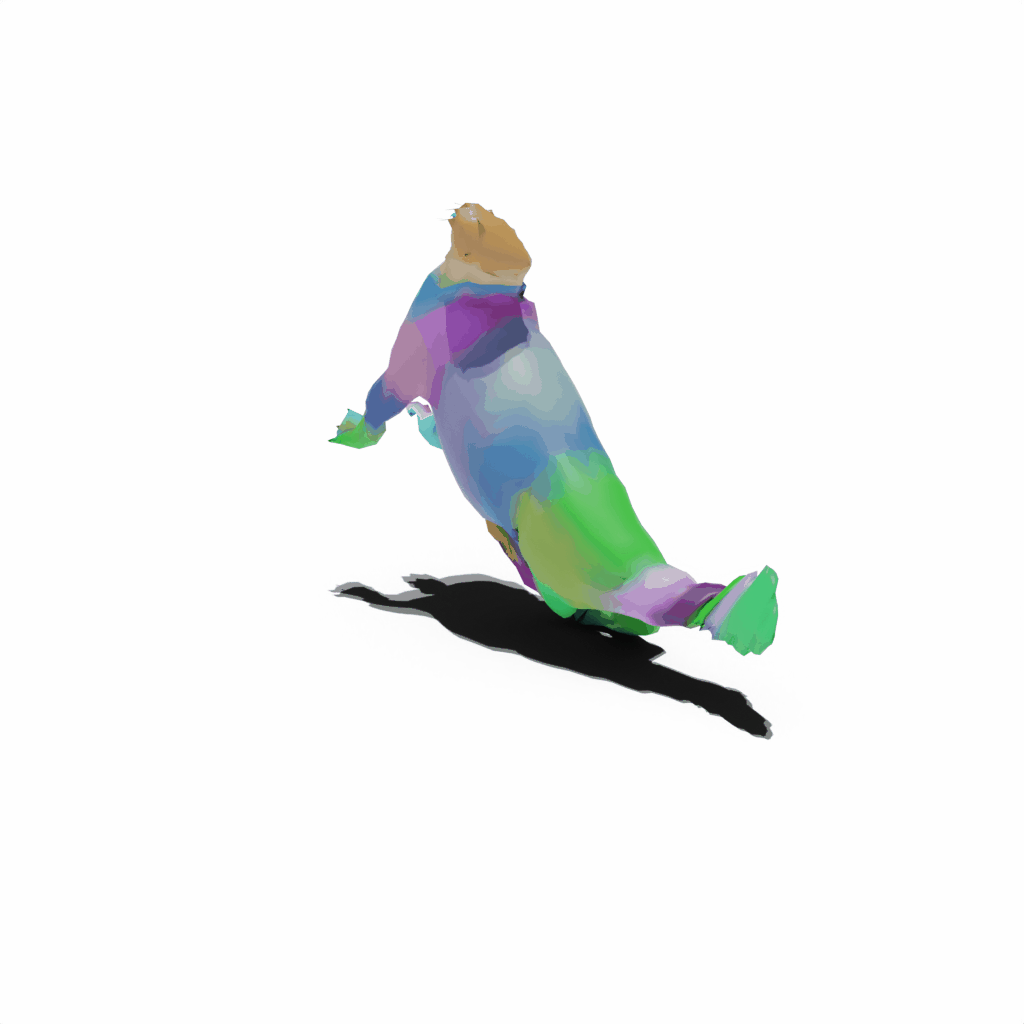

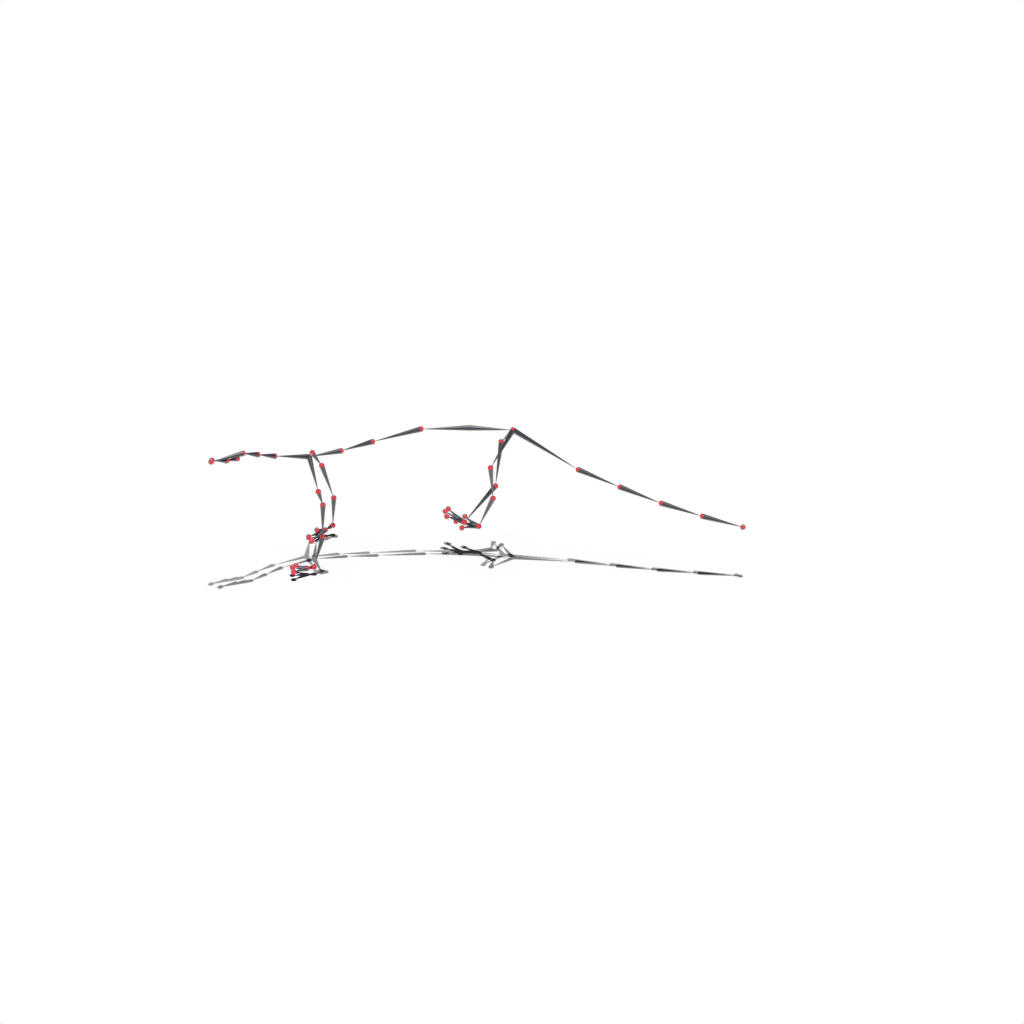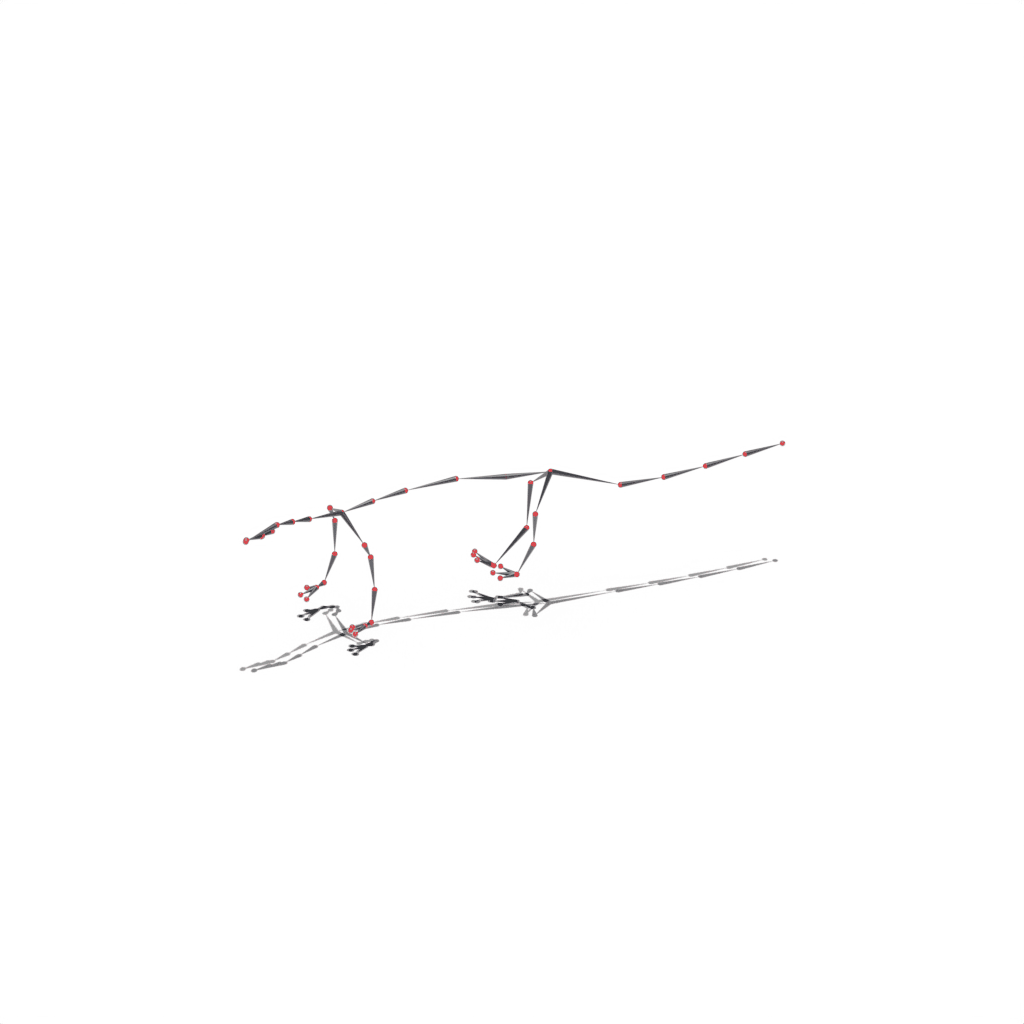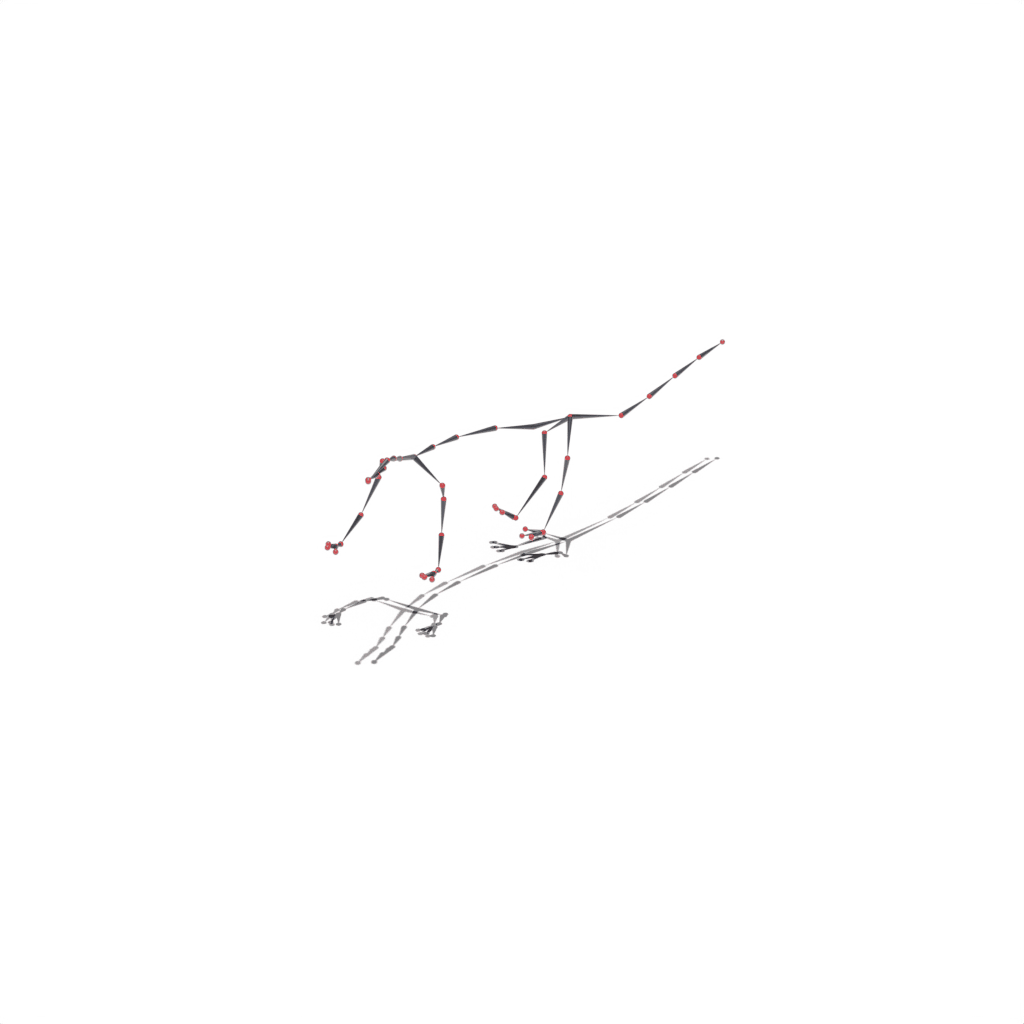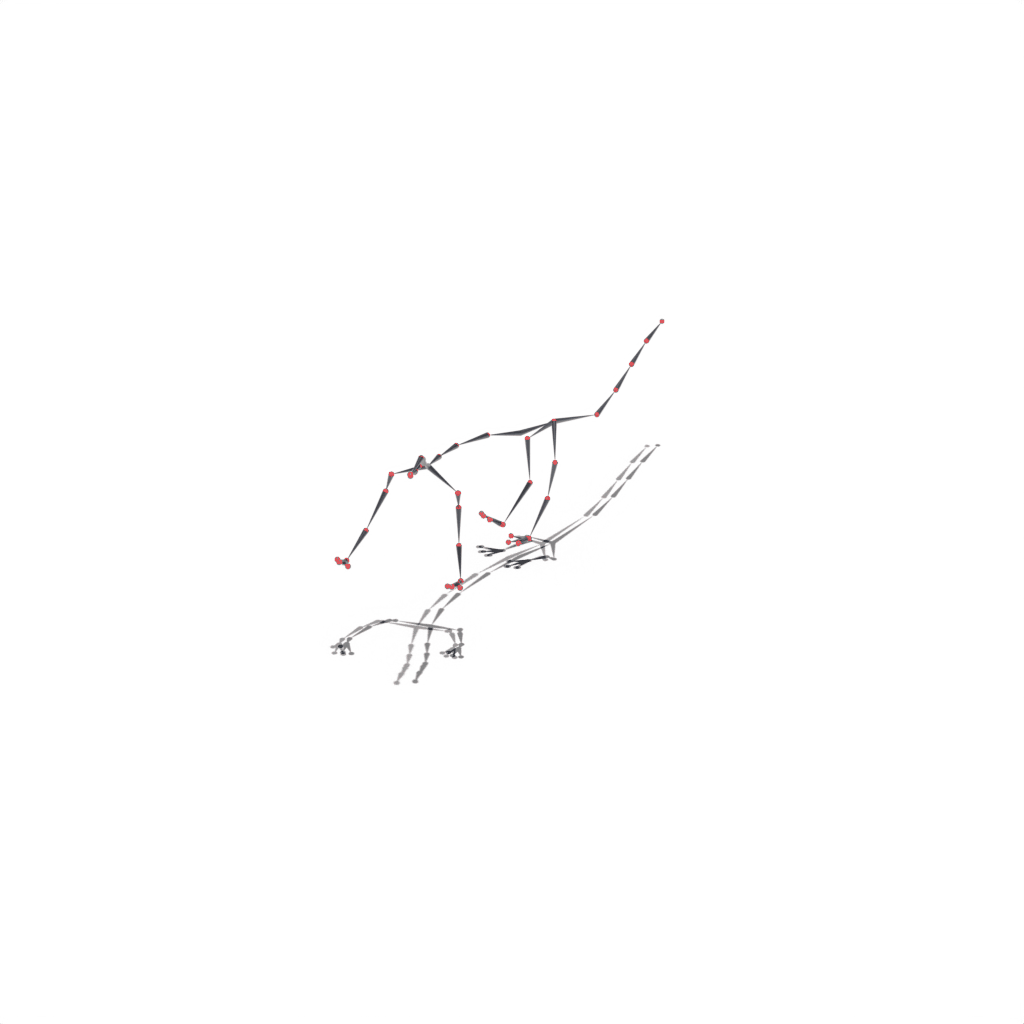
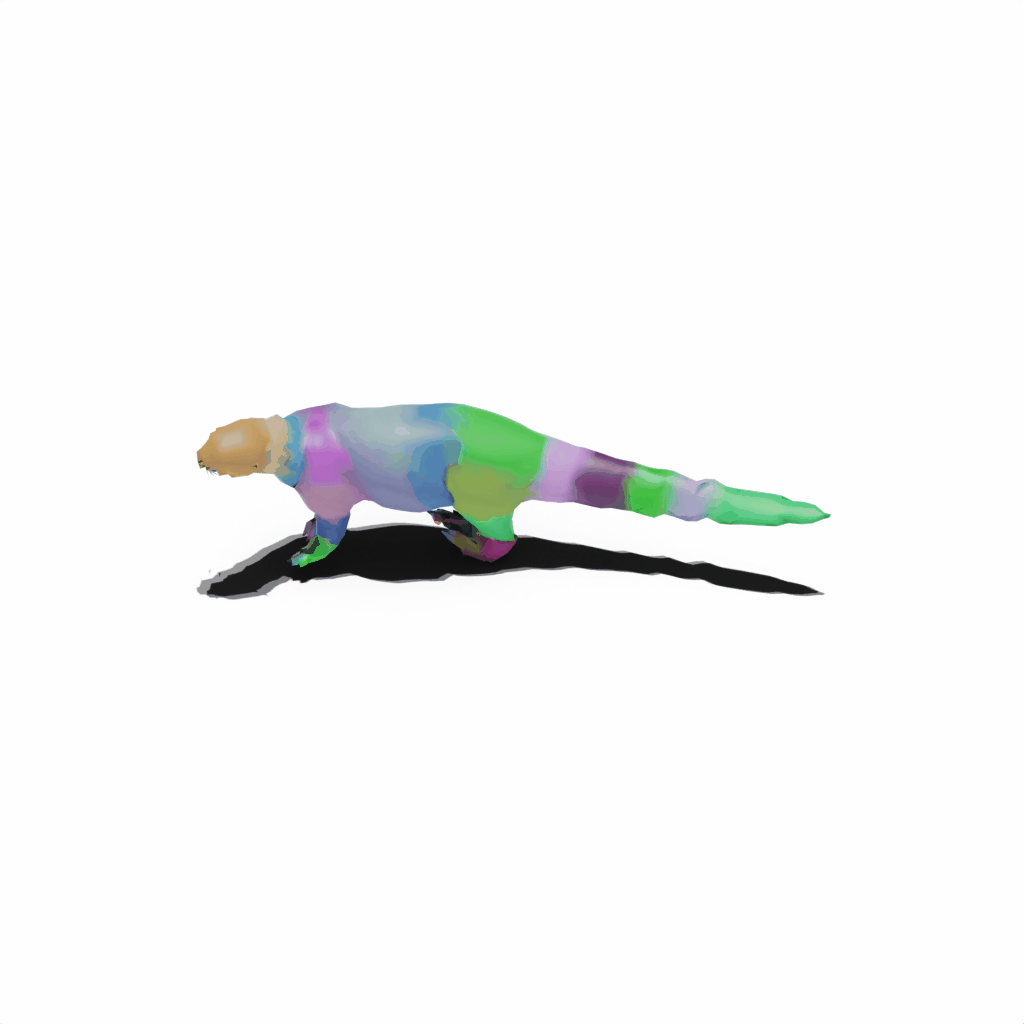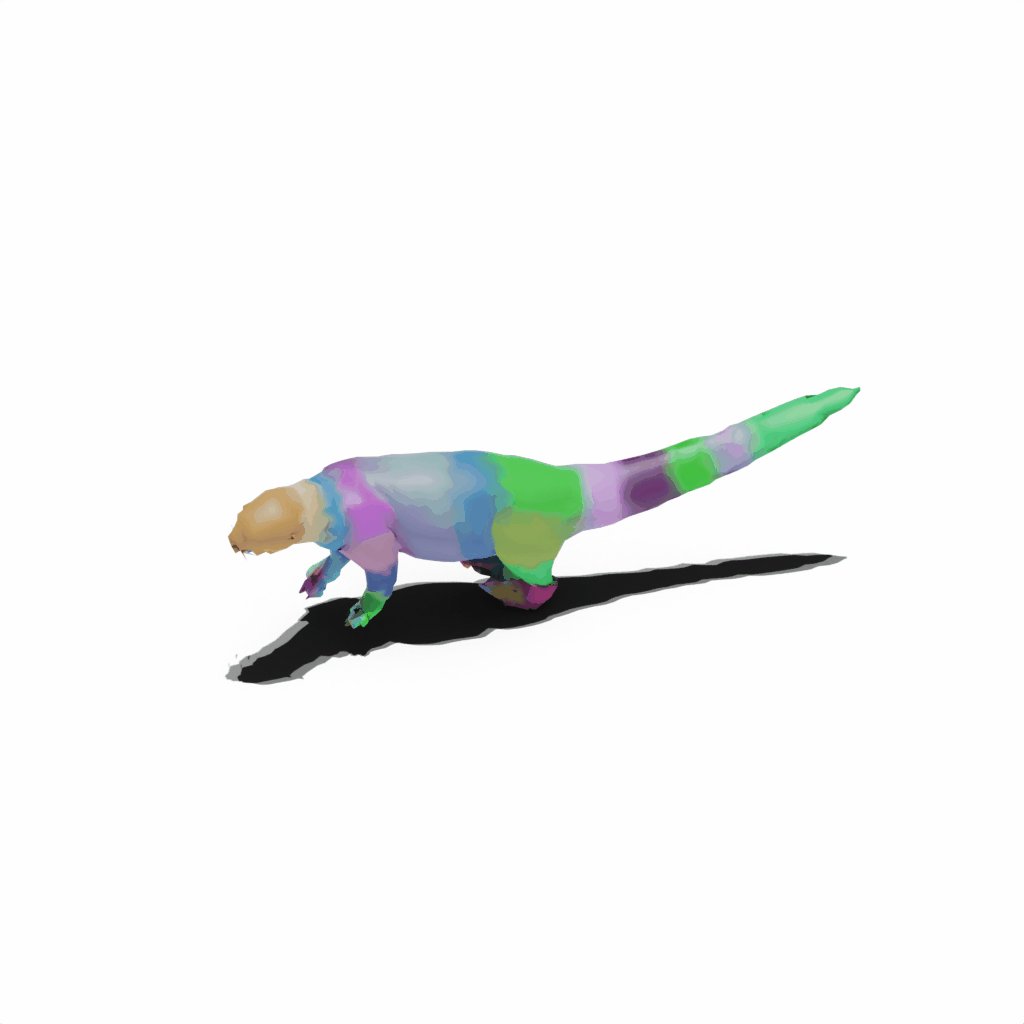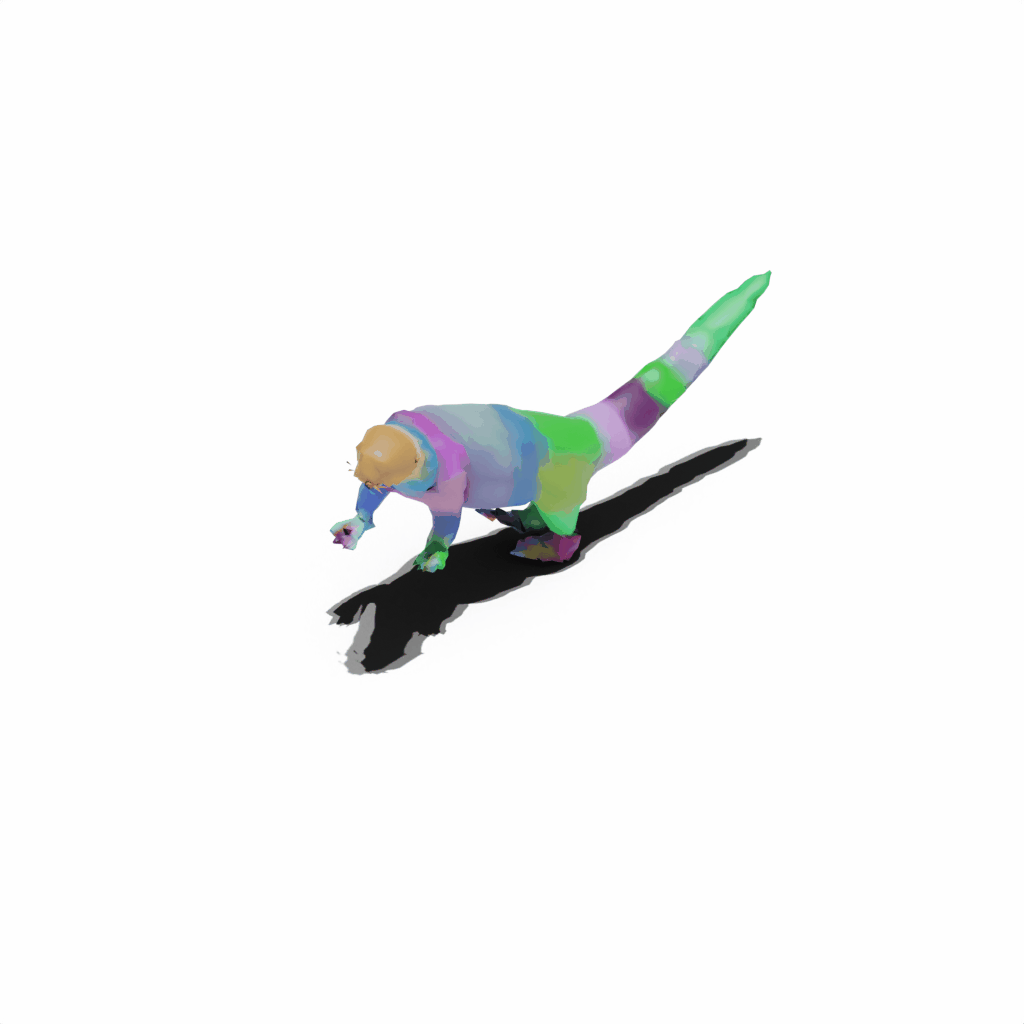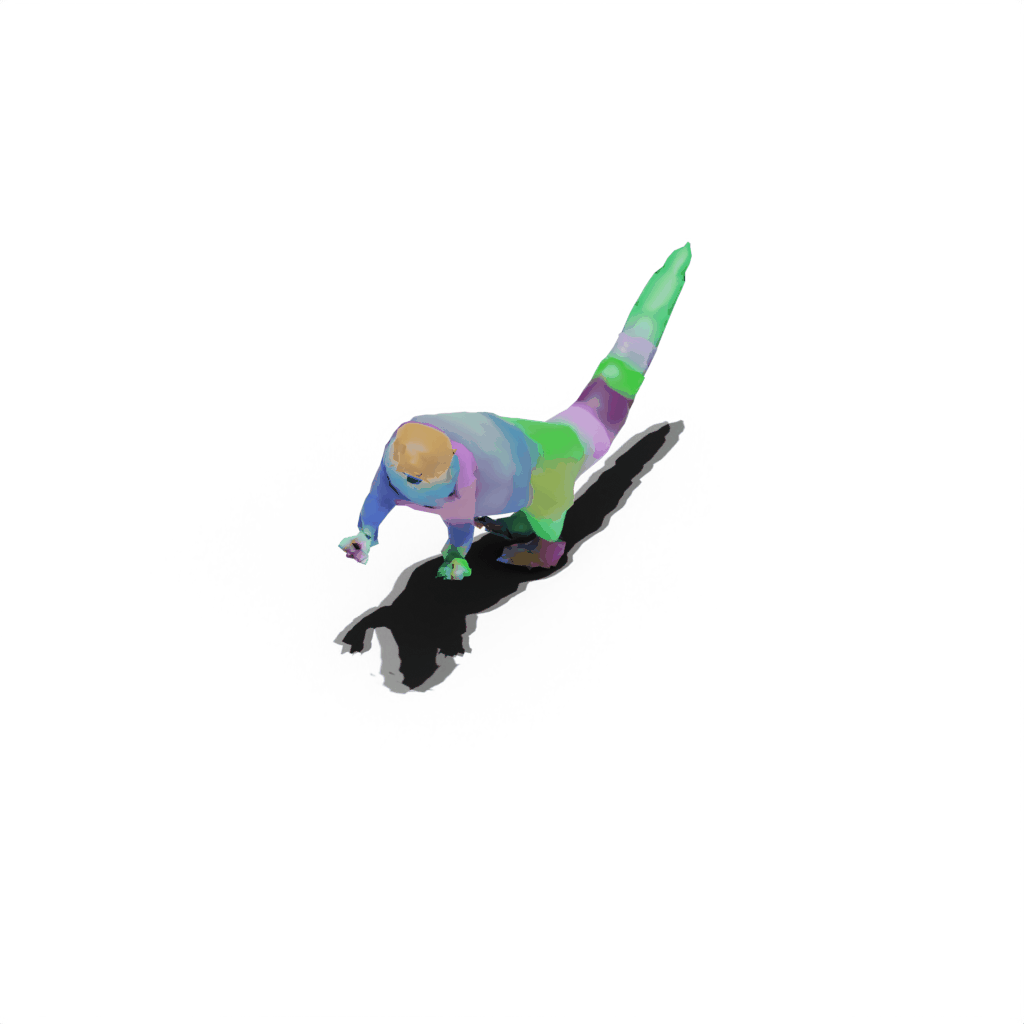
Interactive 3D Reconstruction Results
Bonobo
Wolf
Camel
Cows